MemStore源码分析
MemStore总体的结构比较简单,Object通过Collection的概念来组织Object,每个Collection有两个结构存储Object映射。
下图的MemStore的关键内容,左侧是事务处理函数,右图是主要的类图
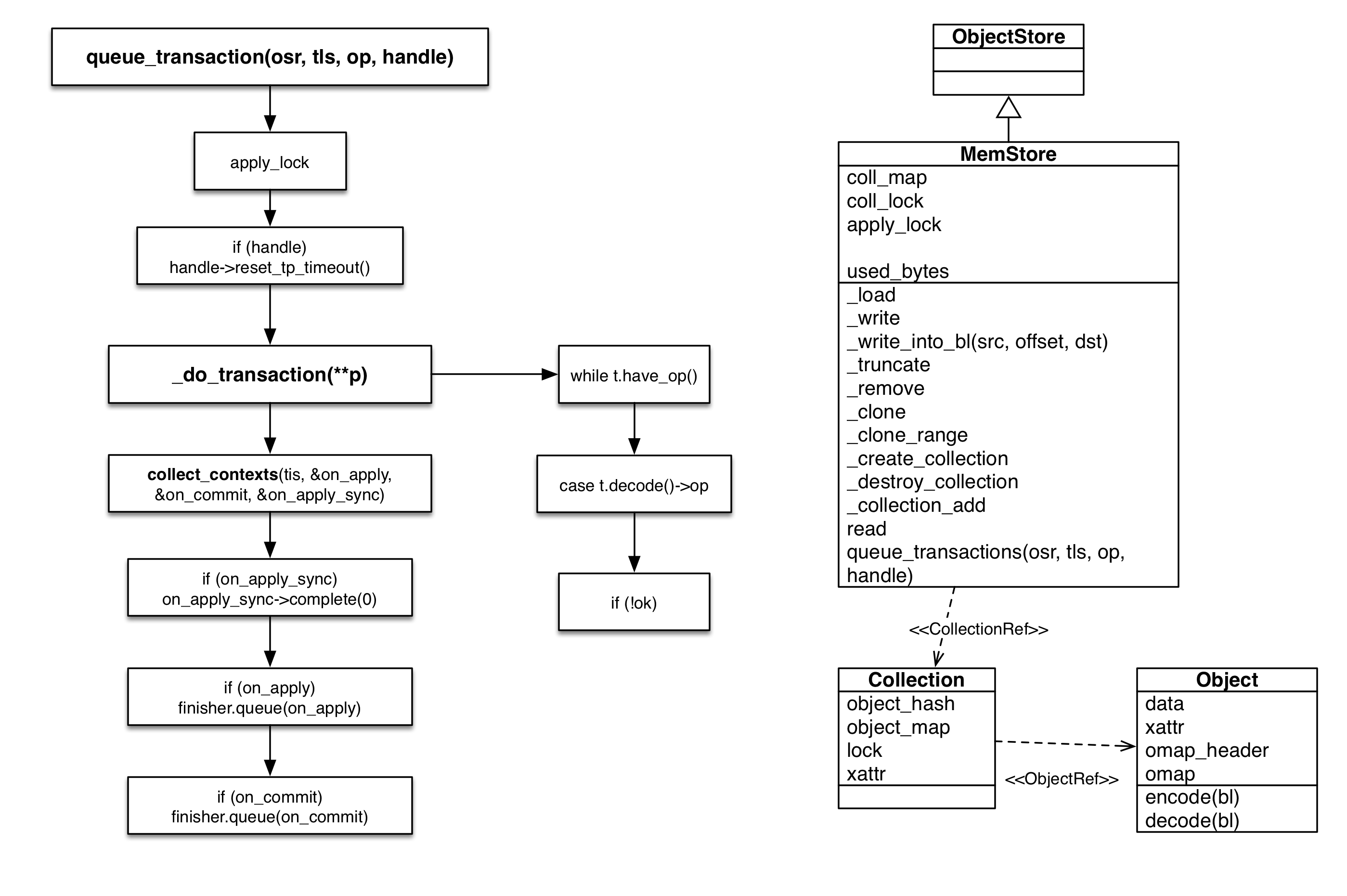
关键变量
- object_hash
object的hash结构,使用了STL的unordered_map,类似于Java的HashMap。 object可以快速定位 - object_map
object的map结构,使用了STL的map,类似于Java的TreeMap,内部是红黑树实现。object可以快速遍历访问 - lock
涉及到object_hash/map 的写修改,都会上锁
还没看的点
1.分多个Collection的作用(对应不同pool?)
2.omap的映射还没整理
关键函数
read(cid,oid,offset,len,bl,op_flags,allow_eio)
读的情况比较简单,有读的请求会直接调用本函数。
主要流程
c=get_collection(cid) -> RLocker (c->lock) -> ObjectRef o=c->get_object(oid)
-> offset检查 –> len检查 –> bl.substr_of(o->data, offset, l)
_load()
通过文件加载collections和object信息到内存
首先读取 ObjectStore path/collections 文件,包含了以path/cid为名字的各个collection文件,再从文件中依次decode出object。_write(cid, oid, offset, len, bl, fadviseflags)
从写事务中decode出各项参数,然后就调用了本函数。
主要流程
c=get_collection(cid)
-> WLock (c->lock)
-> ObjectRef o=c->get_object(oid) (if not exists, then create and add to c )
-> _write_into_bl(bl, offset, &o->data) write bufferlist data into object
_write_into_bl(src, offset, dst)
将src数据写到dst的offset位置后面。
实现步骤,新建bufferlist newdata,先拷贝dst到newdata,如果长度小于offset,则补0,然后将src数据append在newdata后面,最后dst的数据重新映射到newdata_truncate(cid, oid, size)
调整object大小
如果size<o.len,复制o的前面size大小数据到新的bl,然后o重新映射到新的bl;
如果size>o.len,新建size-o.len长度的bl,补0后append在o后面_remove(cid, oid)
从cid的collection的object_map和object_hash中删除oid_clone(cid, oldoid, newoid)
找到newoid对应对象,如果没有则新建。然后将newoid的data,omap_header, omap, xattr映射到oldoid的对应数据。_clone_range(cid, oldoid, newoid, srcoff, len, dstoff)
从oldoid的scroff开始,克隆len长的数据到newoid的dstoff后面。_create_collection(cid)和_destory_collection(cid)
collection的创建和销毁